
Linux常用命令整理
一、文件操作
移动:mv
复制:cp
删除:rm
创建文件夹:mkdir -p参数是即使父目录不存在,递归创建出来文件夹
查找: find 路径 -name 文件名
二、进程管理
1.ps命令
ps - aux|(grep 命令名) 显示所有进程信息,连同命令行
显示结果说明:

主要参数:
| USER | 用户账号 |
|---|---|
| PID | 当前进程ID |
| CPU | 进程占用CPU |
| MEM | 进程占用内存 |
| VSZ | 虚拟内存量Kbytes |
| RSS | 物理内存量KBytes |
| TTY | 于哪一终端运作,如果与终端机无关显示? |
| STAT | 进程状态R运行、S睡眠、T停止、Z僵尸 |
| START | 启动时间 |
| TIME | 实际占用CPU运行时间 |
| COMMAND | 该程序的实际命令 |
三、文件内容查看及操作
tail -fn100 文件 |grep 内容 循环查看日志文件某内容最新消息
快速查找匹配文本grep -Frn 匹配内容 文件名
快速编辑匹配文本sed
格式化文本awk: 如快速输出每一行的第1个和第4个单词
awk ‘{if($6==“42030”) {print} }’ hdp_teu_spat_im_php_access_info.2021042017.*|grep 23653471544838
1.awk
1.1通用格式
awk'{pattern+action}' filename
(其操作为每读取一行执行action一次)
1.2参数详情
1.3举例:
1.3.1打印每一行的第一个文本
awk ‘{print $1}’ file1
1.3.2加入初始和结尾的执行语句
awk ‘BGGEIN{print “我是开头”} {print $1} END{print “结尾”}’
BEGIN、END后面的语句仅执行一次,中间的语句则每读取一次执行一次
1.3.3加入条件语句if
awk { if($5!='“lin”) {print $5} }
过滤每行第5个参数为lin的行,打出其他第5行的参数
2.Sed匹配删除替换指定文本
2.1通用格式
sed -nefri ‘command’ 文件内容
(其操作为每读取一行执行action一次)
2.2参数详情
常用选项: -n∶使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。 -e∶直接在指令列模式上进行 sed 的动作编辑; -f∶直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作; -r∶sed 的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法) -i∶直接修改读取的档案内容,而不是由萤幕输出。
常用命令: a ∶新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ c ∶取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! d ∶删除,因为是删除啊,所以 d 后面通常不接任何咚咚; i ∶插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); p ∶列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~ s ∶取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
2.3举例
假设我们有一文件名为ab。
2.3.1删除某行:
# sed '1d' ab #删除第一行
# sed '$d' ab #删除最后一行
# sed '1,2d' ab #删除第一行到第二行
# sed '2,$d' ab #删除第二行到最后一行
2.3.2显示某行:
# sed -n '1p' ab #显示第一行
# sed -n '$p' ab #显示最后一行
# sed -n '1,2p' ab #显示第一行到第二行
# sed -n '2,$p' ab #显示第二行到最后一行
2.3.3使用模式进行查询:
# sed -n '/ruby/p' ab #查询包括关键字ruby所在所有行
# sed -n '/\$/p' ab #查询包括关键字$所在所有行,使用反斜线\屏蔽特殊含义
2.3.4增加一行或多行字符串:

# cat ab
Hello!
ruby is me,welcome to my blog.
end
# sed '1a drink tea' ab #第一行后增加字符串"drink tea"
Hello!
drink tea
ruby is me,welcome to my blog.
end
# sed '1,3a drink tea' ab #第一行到第三行后增加字符串"drink tea"
Hello!
drink tea
ruby is me,welcome to my blog.
drink tea
end
drink tea
# sed '1a drink tea\nor coffee' ab #第一行后增加多行,使用换行符\n
Hello!
drink tea
or coffee
ruby is me,welcome to my blog.
end
2.3.5代替一行或多行:
# sed '1c Hi' ab #第一行代替为Hi
Hi
ruby is me,welcome to my blog.
end
# sed '1,2c Hi' ab #第一行到第二行代替为Hi
Hi
end
2.3.6替换一行中的某部分
格式:sed ’s/要替换的字符串/新的字符串/g' (要替换的字符串可以用正则表达式)
# sed -n '/ruby/p' ab | sed 's/ruby/bird/g' #替换ruby为bird
# sed -n '/ruby/p' ab | sed 's/ruby//g' #删除ruby
2.3.7插入:
# sed -i '$a bye' ab #在文件ab中最后一行直接输入"bye"
# cat ab Hello! ruby is me,welcome to my blog. end bye
2.3.8删除匹配行:
sed -i '/匹配字符串/d' filename (注:若匹配字符串是变量,则需要“”,而不是‘’。记得好像是)
2.3.9替换匹配行中的某个字符串:
sed -i '/匹配字符串/s/替换源字符串/替换目标字符串/g' filename
3.grep匹配文本
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep [options]
主要参数 [options]主要参数:
-c:只输出匹配行的计数。
-I:不区分大 小写(只适用于单字符)。 -h:查询多文件时不显示文件名。 -l:查询多文件时只输出包含匹配字符的文件名。 -n:显示匹配行及 行号。 -s:不显示不存在或无匹配文本的错误信息。 -v:显示不包含匹配文本的所有行。 pattern正则表达式主要参数: \: 忽略正则表达式中特殊字符的原有含义。 ^:匹配正则表达式的开始行。 $: 匹配正则表达式的结束行。 <:从匹配正则表达 式的行开始。 >:到匹配正则表达式的行结束。 [ ]:单个字符,如[A]即A符合要求 。 [ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。 。:所有的单个字符。
- :有字符,长度可以为0。
5.2 grep简单使用
显示所有以d开头的文件中包含 test的行:
$ grep 'test' d*
显示在aa,bb,cc文件中匹配test的行:
$ grep 'test' aa bb cc
输出匹配行的计数:
grep -c "48" data.doc #输出文档中含有48字符的行数
显示匹配行和行数:
grep -n "48" data.doc #显示所有匹配48的行和行号
显示非匹配的行:
grep -vn "48" data.doc #输出所有不包含48的行
显示非匹配的行:
grep -vn "48" data.doc #输出所有不包含48的行
大小写敏感:
grep -i "ab" data.doc #输出所有含有ab或Ab的字符串的行
5.3 grep正则表达式的应用 (注意:最好把正则表达式用单引号括起来)
grep '[239].' data.doc #输出所有含有以2,3或9开头的,并且是两个数字的行
不匹配测试:
grep '^[^48]' data.doc #不匹配行首是48的行
使用扩展模式匹配:
grep -E '219|216' data.doc
显示所有包含每个字符串至少有5个连续小写字符的字符串的行:
$ grep '[a-z]\{5\}' aa
如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.),这些字符后面紧跟着 另外一个es(\1),找到就显示该行。如果用egrep或grep -E,就不用”\”号进行转义,直接写成’w(es)t.\1′就可以了:
$ grep 'w\(es\)t.*\1' aa
5.4 正则表达式 符号表示

a

四、解压文件
| 文件格式 | 命令 |
|---|---|
| tar | 解压tar - xvf 压缩tar - cvf 压缩目标文件 压缩文件 |
| tar.gz | 解压tar -zxvf 压缩tar -czf |
| zip | 解压zip 压缩后文件名 压缩unzip需要下载zip |
| rar | 解压rar a [压缩后文件名] [被压缩文件] 压缩unrar e需要下载rar |
五、检测网络
netstat -ant n表示以ip的形势显示而非域名 a显示所有socket默认只显示connected状态的 t监听tcp端口
六、查看磁盘使用情况
1.统计磁盘整体情况
df -h
2.统计具体文件夹的磁盘使用情况
du –max-depth=1 -h查看当前目录下的每个文件夹的使用情况
du -sh显示当前目录整体占用情况
七、本机和服务器之间的操作
1.nc
目的主机监听端口 nc -l 监听端口<未使用端口> > 要接收的文件名 举例: nc -l 4444 > cache.tar.gz源主机发起请求 nc 目的主机ip 目的端口 < 要发送的文件 举例: nc 192.168.0.85 4444 < /root/cache.tar.gz
传输过程是 目的主机接受文件完成后回自动关闭监听链接
八、linux输出重定向
关于shell中:>/dev/null 2>&1 详解
shell中可能经常能看到:>/dev/null 2>&1 。命令的结果可以通过%>的形式来定义输出
分解这个组合:“>/dev/null 2>&1” 为五部分。
1:> 代表重定向到哪里,例如:echo “123” > /home/123.txt 2:/dev/null 代表空设备文件 3:2> 表示stderr标准错误 4:& 表示等同于的意思,2>&1,表示 2 的输出重定向等同于 1 5:1 表示stdout标准输出,系统默认值是1,所以">/dev/null"等同于 “1>/dev/null”
因此,>/dev/null 2>&1也可以写成 “ 1> /dev/null 2> &1 ”
那么 &>/dev/null 语句执行过程为: 1>/dev/null :首先表示标准输出重定向到空设备文件,也就是不输出任何信息到终端,说白了就是不显示任何信息。 2>&1 :接着,标准错误输出重定向 到标准输出,因为之前标准输出已经重定向到了空设备文件,所以标准错误输出也重定向到空设备文件。
九、系统资源统计
9.0综合
9.0.1 top
top
接收参数
-p 指定要观察的pid
交互命令
在 top 执行过程当中可以使用的按键指令:
数字1 显示所有核的情况
? :显示在 top 当中可以输入的按键指令;
P :以 CPU 的使用资源排序显示;
M :以 Memory 的使用资源排序显示;
N :以 PID 来排序喔!
T :由该 Process 使用的 CPU 时间累积 (TIME+) 排序。
k :给予某个 PID 一个讯号 (signal)
r :给予某个 PID 重新制订一个 nice 值。
q :离开 top 软件的按键
H :显示线程
参数含义
第一行

目前时间、运行时间、登录人数
1,5,15分钟每个cpu运行的进程数
第二行

程序运行总量和个别程序运行状态
第三行

cpu负载情况, wa表示等待I/O wait比例
第四五行

swap要尽量少,buffer/cached是 读写磁盘用作缓冲的内存,当内存实在不够用时会释放该部分的内存
所以实际可用内存= free+buffer+cached
top下半部分
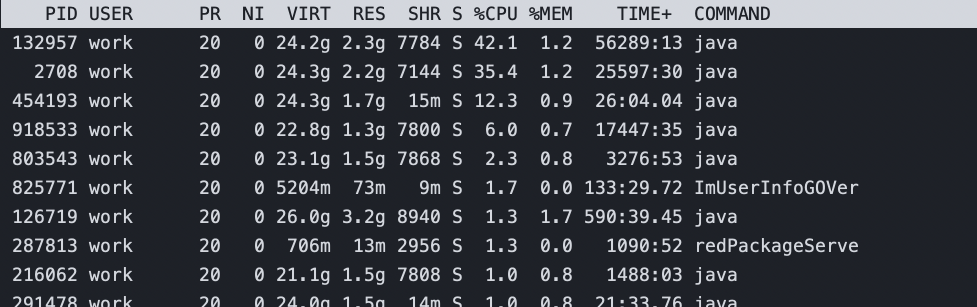
PID :每个 process 的 ID 啦!
USER:该 process 所属的使用者;
PR :Priority 的简写,程序的优先执行顺序,越小越早被执行; NI :Nice 的简写,与 Priority 有关,也是越小越早被执行; %CPU:CPU 的使用率;
%MEM:内存的使用率;
TIME+:CPU 使用时间的累加
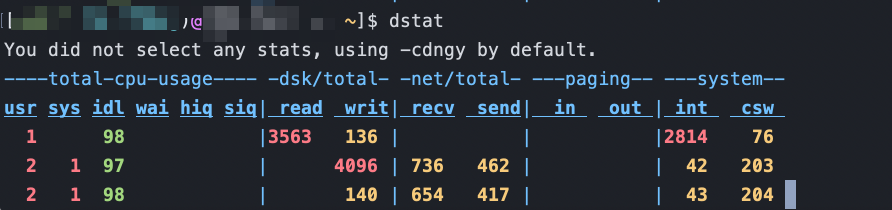
9.0.2 dstat
//实时的监控cpu、磁盘、网络、IO、内存,甚至还有socket等情况,生成csv表格
dstat
-c:显示CPU系统占用,用户占用,空闲,等待,中断,软件中断等信息。
-C:当有多个CPU时候,此参数可按需分别显示cpu状态,例:-C 0,1 是显示cpu0和cpu1的信息。
-d:显示磁盘读写数据大小。
-D hda,total:include hda and total。
-n:显示网络状态。
-N eth1,total:有多块网卡时,指定要显示的网卡。
-l:显示系统负载情况。
-m:显示内存使用情况。
-g:显示页面使用情况。
-p:显示进程状态。
-s:显示交换分区使用情况。
-S:类似D/N。
-r:I/O请求情况。
-y:系统状态。
--ipc:显示ipc消息队列,信号等信息。
--socket:用来显示tcp udp端口状态。
-a:此为默认选项,等同于-cdngy。
-v:等同于 -pmgdsc -D total。
--output 文件:此选项也比较有用,可以把状态信息以csv的格式重定向到指定的文件中,以便日后查看。例:dstat --output /root/dstat.csv & 此时让程序默默的在后台运行并把结果输出到/root/dstat.csv文件中。
9.1磁盘
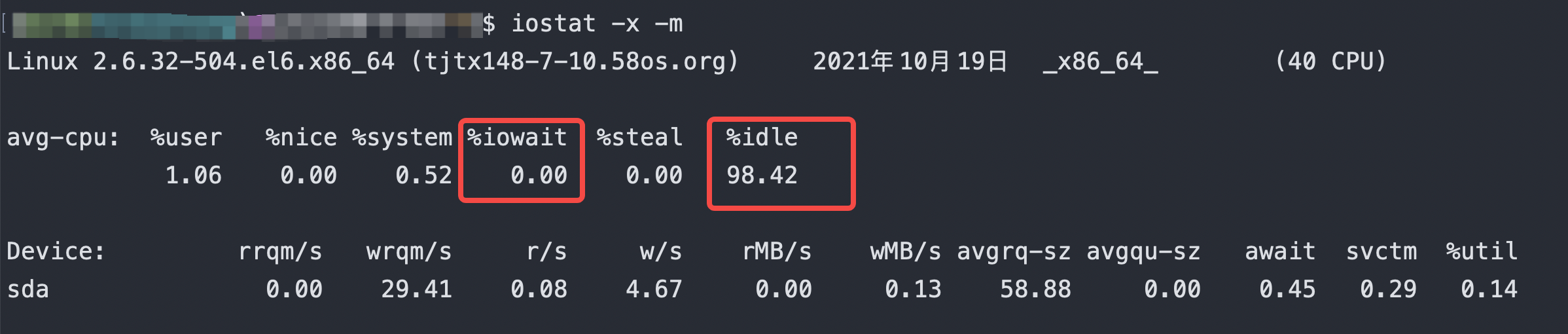
iostat
[-k -m]显示读写单位
[-d] 2 每2秒1次
[-x]可以显示更详细信息
| 选项 | 说明 |
|---|---|
| %user | CPU在用户态执行进程的时间百分比。 |
| %nice | CPU在用户态模式下,用于nice操作,所占用CPU总时间的百分比 |
| %system | CPU处在内核态执行进程的时间百分比 |
| %iowait | CPU用于等待I/O操作占用CPU总时间的百分比 |
| %steal | 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟CPU的百分比 |
| %idle | CPU空闲时间百分比 |
- 若 %iowait 的值过高,表示硬盘存在I/O瓶颈
- 若 %idle 的值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量
- 若 %idle 的值持续低于1,则系统的CPU处理能力相对较低,表明系统中最需要解决的资源是 CPU使用比例iostat -x svctm %util
9.2cpu
9.3网卡流量
// 实时显示网卡流量信息
nload
9.4内存
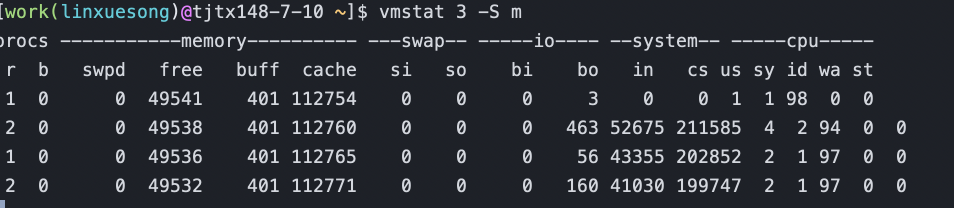
vmstat
vmstat 3 10 每3秒1次,一共10次,没10不会停
-S k|m 以kb、mb单位显示内存
字段说明:
Procs(进程)
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b: 等待IO的进程数量。
Memory(内存)
swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
free: 空闲物理内存大小。
buff: 用作缓冲的内存大小。
cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap
si: 每秒从交换区写到内存的大小,由磁盘调入内存。
so: 每秒写入交换区的内存大小,由内存调入磁盘。
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO(现在的Linux版本块的大小为1kb)
bi: 每秒读取的块数
bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示)
us: 用户进程执行时间百分比(user time)
us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 内核系统进程执行时间百分比(system time)
sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa: IO等待时间百分比
wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id: 空闲时间百分比
综合:top、、dstat
十、其他
1.在终端开发应用程序,如使用文本编辑器打开文本文件 open -a <应用程序> <文件名>
2.打印文件树 方法一:find . -print | sed -e ’s;[^/]*/;|;g;s;|; |;g' 方法二:下载tree命令




